


The Developer's Guide to Production-Grade LLM Apps
Advanced Techniques for Maximizing LLM Performance


Developing LLM applications is one thing; deploying them successfully in production is another. For developers, the path from a promising prototype to a scalable, stable product is often cluttered with obstacles. These range from managing costs to ensuring the model's accuracy against issues like bias or hallucination.
When working on a new AI project, the initial focus is often on optimizing quality and delivering the best user experience. Once this is achieved, the next crucial step is optimizing costs without compromising the established quality.
This post cuts through the complexity, offering a developer's guide to maximizing accuracy as you transition your LLM applications from the dev environment to the rigors of production.
Prompt Engineering: The Starting Block
Every LLM journey begins with prompt engineering. It's the first step that gets your model off the ground by rapidly prototyping and iterating through initial conversations. Consider this phase your LLM's sandbox period—it's about exploring the capabilities, setting up the basics, and rolling out a version that's ready for real-world feedback. It's not just about getting the LLM to respond; it's about crafting those responses to be coherent, contextually relevant, and a stepping stone for more complex interactions.
Prompt engineering isn't just about asking; it's about asking well.
To further refine your prompts, consider these strategies:
Write Clear Instructions: Craft system messages and prompts that are precise and unambiguous. The clarity of your prompts significantly influences the LLM's output, ensuring that the model has a solid understanding of the task at hand.
Split Complex Tasks: Break down intricate tasks into simpler subtasks. This allows the LLM to tackle each component with focus, making the overall task less daunting and more manageable.
Leverage Few-Shot Learning: After establishing the basics, Few-Shot Learning empowers the model to generalize from a few examples. This method is invaluable for rapidly expanding the LLM's capabilities without the need for extensive training data, acting as an accelerator in your LLM's journey from simple responses to complex conversations.
Integrate Self-Explanation in Responses: When crafting prompts, include a request for the LLM to not only provide an answer but also to explain its reasoning within the same response. This technique ensures that the model's output is not just accurate, but also that the underlying logic is sound and comprehensible
Use AI to Optimize Your Prompts: When prompts are constructed with AI assistance, they tend to be clearer and more aligned with the model's processing, thereby enhancing the accuracy of the responses.

The Role of Evals: Your North Star
Evaluations are a cornerstone in AI development, offering a measure of performance that focuses on accuracy and the quality of outcomes.
In the non-deterministic world of AI, understanding and continually monitoring these performance metrics is crucial.
Systematic Approach to AI Evaluations
Initially, evaluations might start off as manual explorations, where developers input various prompts to observe the AI's responses.
Over time, as performance stabilizes, it becomes important to shift to a more structured evaluation using carefully curated datasets.

Dataset Utilization for In-depth Testing
The creation of a tailored dataset is a foundational step toward more rigorous testing. It allows for comprehensive scrutiny of the AI's responses, with a focus on manual review to ensure high-quality output. The process of evaluating datasets typically involves:
Running LLMs over the dataset: Test your LLM with each data point in your dataset. This step is about checking how well the LLM handles each specific scenario you've included.
Manual Review: Don't rely solely on automated tests. Manually go through the LLM's responses. This helps catch nuances and subtleties that machines might miss.
Feedback Mechanisms: Use a system within your evaluation setup to record feedback. This makes it easier to spot trends, identify issues quickly, and refine your LLM continually.
Refining Evaluations with AI Assessments
For a scalable evaluation process, automated metrics can be employed to guide the review, especially as the volume of data increases. These metrics can help identify areas that require special attention, though they should be used as guides rather than definitive measures of performance.
Metrics to evaluate:


Human Evaluation as the Gold Standard
The ultimate measure of an AI's performance still relies on human evaluation. This process involves:
Subjective Analysis: Assessing elements like creativity, humor, and user engagement that automated systems may not fully capture.
Validation of Automated Metrics: Confirm that the automated evaluations are aligned with human judgment and that the AI's outputs meet the expected standards.
Feedback Integration and Model Refinement
Feedback from human evaluations can be systematically integrated into the development process. This not only helps in fine-tuning the AI model to enhance its accuracy but also aids in adapting the model for cost efficiency or quality improvement.
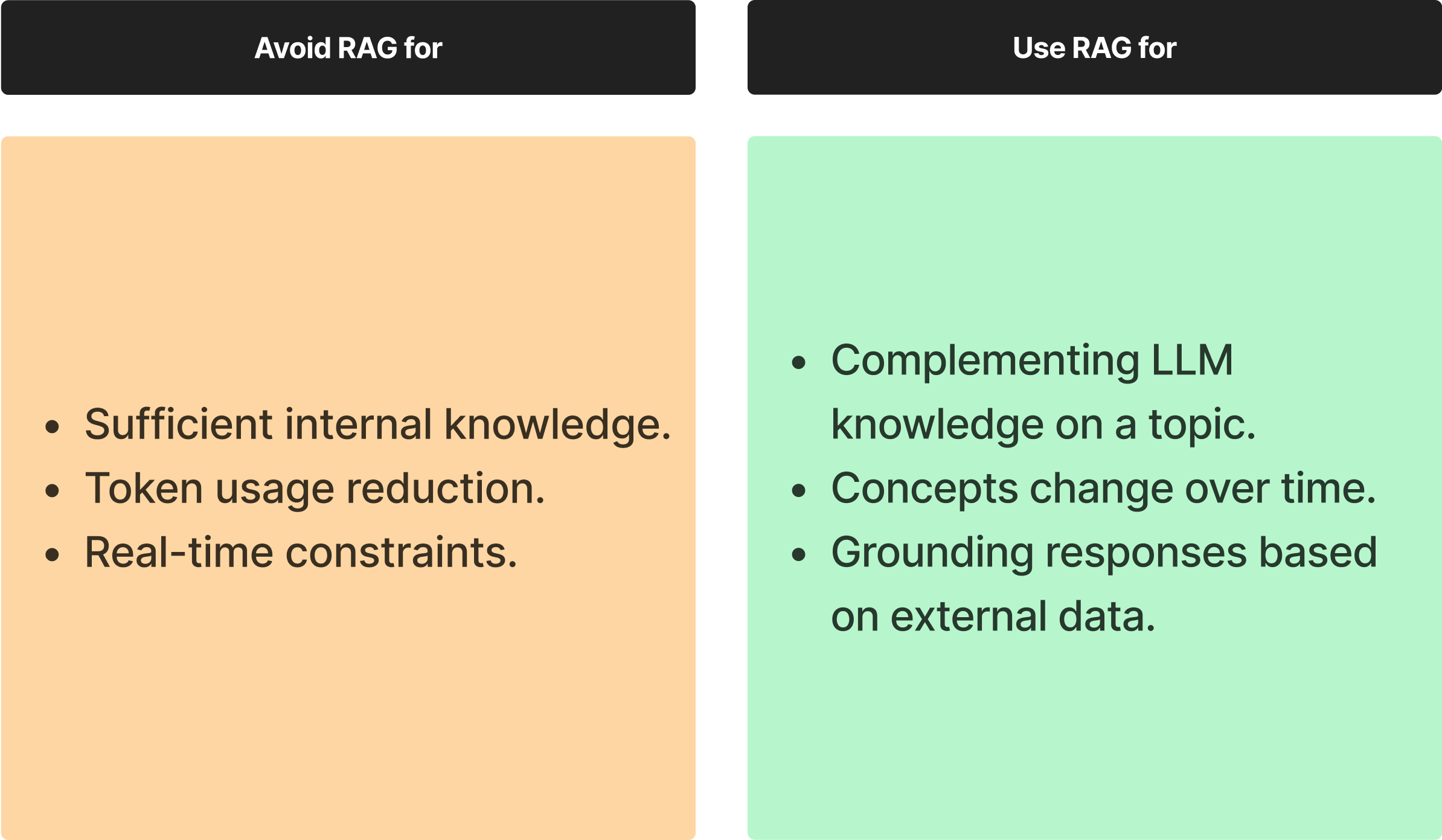
RAG: Contextual Depth When Needed

RAG comes into play when your LLM needs an extra layer of context. This method is about leveraging external knowledge to enhance the model's responses. However, it's not always the right tool. Invoke RAG when evaluations reveal knowledge gaps or when the model requires a wider breadth of context.
Techniques to Experiment With:
Iterative Retrieval: Experiment with iterative retrieval strategies, where the LLM can ask follow-up questions to refine its search and improve the relevance of the information retrieved. example.
Chunking Experiments: Break down your data into manageable chunks and create embeddings for these smaller pieces. This can potentially improve the granularity of the retrieval process and provide more targeted responses. example.
Reranking: After the initial retrieval, use a secondary model to rerank the results based on additional criteria for relevance. A classification step can further categorize responses to fine-tune the selection process for the end-user. example.

Hybrid Data-Enabled Retrieval (HyDE): Enhance RAG's capabilities by generating hypothetical documents and using those for embedding lookup. example.
Fine-Tuned Embeddings: Customize the embedding layers of your LLM to better capture the subtleties of your specific dataset, allowing for a more nuanced understanding and retrieval of information that is closely matched to the user's request. example.
Query Expansion: Utilize specialized functions that can expand the scope of your LLM's understanding by modifying or augmenting queries with additional terms, synonyms, or related concepts, ensuring a wider net is cast for information retrieval.

Fine-Tuning: The Art of Specialization

Fine-tuning is about specialization, adapting your LLM to your application's specific task, unique voice and context. The decision to fine-tune comes after you've gauged your model's proficiency through thorough evaluations. When your LLM needs to understand industry-specific jargon, maintain a consistent personality, or provide in-depth answers that require a deeper understanding of a particular domain, fine-tuning is your go-to process.

Fine-tuning an LLM is a nuanced process that can significantly elevate the performance of your model—if done correctly. However, there are several common pitfalls that you need to be aware of to ensure your fine-tuning efforts don't go astray. Let's delve into these pitfalls and discuss how to circumvent them:
Insufficient Training Data: The Quantity-Quality Equilibrium
One of the most prevalent issues is the scarcity of training data. LLMs thrive on large, diverse datasets; thus, fine-tuning with inadequate data can lead to overfitting where the model performs well on the training data but poorly on unseen data. Aim for a robust dataset with at least 1,000 quality examples for each task you're training the model to perform.
Unbalanced Training Sets: The Bias Dilemma
A dataset that doesn't represent the variety or distribution of real-world scenarios can skew your model's outputs. This often occurs with class imbalances where certain outcomes are overrepresented. Techniques like oversampling the underrepresented classes can help to balance your dataset and mitigate potential biases.
Reusing Public Data: The New Signal Imperative
LLMs have typically been exposed to vast swathes of public data during initial training phases. Relying on these datasets for fine-tuning is redundant and can limit your model's ability to learn. Focus on incorporating unique, proprietary data that can teach the model something new.
Poor Prompt Engineering: The Clarity Commandment
The quality of your prompts is instrumental in guiding the LLM's learning path. Vague or ambiguous prompts can result in a model that generalizes poorly. Invest time in crafting clear, context-rich prompts and iterate based on the model's responses to hone their effectiveness.
Not Evaluating Incrementally: The Continuous Oversight
A common oversight in fine-tuning is the "set it and forget it" approach. Without regular evaluations, you might not detect issues until it's too late. Implement a system for continuous testing and validation at various stages of fine-tuning to ensure quality and performance.
By steering clear of these pitfalls, you lay a solid foundation for fine-tuning success. Now, let's explore state-of-the-art training methodologies that can further enhance your LLM's accuracy and reliability.
When You Need All
Finetuning, RAG, and prompt engineering are all necessary tools for improving your LLM until it meets your needs. Using all means changing your LLM from the inside and the outside.
When prompt engineering has laid the groundwork, and RAG has expanded the context, fine-tuning with additional RAG content in the training examples can be transformative. This approach is about reinforcing the model's foundational knowledge with the rich, contextual details provided by RAG, leading to a finely-tuned model that's ready for the demands of a production environment.

Closing Thoughts
Building LLMs for production is an intricate dance of precision engineering and deliberate decision-making. It’s a craft that requires a strong foundation in prompt engineering, the guidance of a robust evaluation suite, the contextual depth provided by RAG, and the bespoke refinement of fine-tuning.
Keep iterating and refining, and let your suite of evaluations guide you to mastery in LLM development. Embrace these challenges as opportunities to innovate and lead in the field of AI development.
